AMD releases ROCm 6.2: will enable the performance of the new generation of AI a
Whether you are engaged in research on cutting-edge AI models, the development of new generations of artificial intelligence applications, or complex optimization simulations, this new version provides you with significant enhancements in performance, efficiency, and scalability. In this blog post, we will delve into the five major core feature improvements of this release, which, along with the enhancement of functionalities, have made this version transformative, thereby solidifying AMD ROCm's leading position as a development platform for artificial intelligence and high-performance computing.
Expanded vLLM Support in ROCm 6.2 — Enhancing AI Inference Capabilities on AMD Instinct Accelerators
AMD is expanding support for vLLM to enhance the efficiency and scalability of AI models on AMD Instinct accelerators. Designed specifically for large language models (LLMs), vLLM addresses key inference challenges such as efficient multi-GPU parallel computation, reducing memory resource usage, and minimizing computational bottlenecks. Customers can enable various upstream features in vLLM, such as multi-GPU parallel computation and FP8 KV caching (inference), by following the steps provided in the ROCm documentation to tackle relevant development challenges. To access cutting-edge feature capabilities, the ROCm/vLLM branch also offers advanced experimental features, such as FP8 GEMMS (matrix multiplication operations using 8-bit floating-point numbers) and the "custom decoding pagination attention" mechanism. To utilize these features, follow the steps provided here, and when cloning the git repository, select the rocm/vllm branch. Alternatively, obtain it through a dedicated Docker file (click here to get it).
Advertisement
With the release of ROCm 6.2, new and existing users of AMD Instinct can confidently integrate vLLM into their AI pipelines, enjoying the performance and efficiency improvements brought by the latest features.
Bitsandbytes Quantization Technology in ROCm — Enhancing AI Training and Inference Capabilities on AMD Instinct, Improving Memory Efficiency and Performance
The Bitsandbytes quantization library supported by AMD ROCm has brought revolutionary changes to AI development, significantly improving memory efficiency and performance on AMD Instinct GPU accelerators. Utilizing an 8-bit optimizer reduces memory consumption during AI training, allowing developers to handle more complex models with limited hardware resources. The "LLM.Int8()" quantization technique optimizes AI, enabling large language models (LLMs) to be deployed on systems with smaller memory capacities. Low-bit quantization technology accelerates AI training and inference, thereby enhancing overall efficiency and productivity.
Bitsandbytes quantization technology, by reducing memory usage and computational requirements, allows more users to experience advanced AI capabilities, lowers the cost of use, achieves democratization of AI development, and expands new opportunities for innovation. Its scalability effectively manages larger models within existing hardware limitations while maintaining accuracy close to 32-bit precision versions.
Developers can easily integrate Bitsandbytes with ROCm by following the instructions in this link, allowing for efficient AI model training and inference on AMD Instinct GPU accelerators, while reducing memory and hardware requirements.
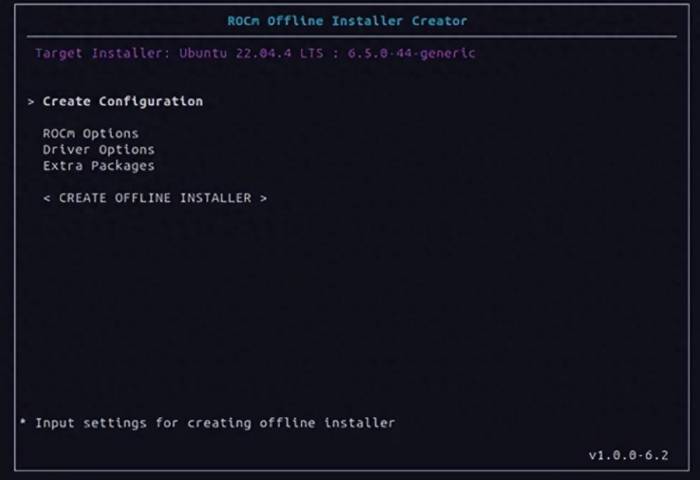
New Offline Installer Creation Tool — Simplifying the ROCm Installation Process
The ROCm offline installer creator provides a complete solution for systems without internet access or local repository mirrors, thereby simplifying the installation process. It creates a single installer file that includes all necessary dependencies and offers a user-friendly graphical interface, allowing easy selection of ROCm components and versions, making deployment straightforward. The tool reduces the complexity of managing multiple installation tools by integrating functionalities into a unified interface, improving efficiency and consistency. Additionally, it automates post-installation tasks, such as user group management and driver handling, helping to ensure the correctness and consistency of the installation.The ROCm Offline Installer Creator downloads and packages all relevant files from AMD repositories and operating system package managers, helping to ensure that the installation process is correct and consistent, thereby reducing the risk of errors and improving overall system stability. It is particularly suitable for systems without internet access and also provides IT administrators with a simplified and efficient installation process, making the deployment of ROCm in various environments easier than ever before.
The all-new Omnitrace and Omniperf performance analysis tools (Beta version) — leading the revolution in AI (Artificial Intelligence) and HPC (High-Performance Computing) development within AMD ROCm
The all-new Omnitrace and Omniperf performance analysis tools (Beta version) will lead a revolution in AI and HPC development within ROCm by providing comprehensive performance analysis and streamlined development workflows.
Omnitrace offers a holistic view of system performance across CPUs, GPUs, Network Interface Controllers (NICs), and network fabrics, helping developers identify and resolve bottlenecks, while Omniperf provides detailed GPU kernel analysis for fine-tuning. Together, these tools optimize both the overall application performance and the performance of specific computational kernels, supporting real-time performance monitoring, which aids developers in making informed decisions and adjustments throughout the development process.
By addressing performance bottlenecks, they help ensure efficient utilization of resources, ultimately leading to rapid AI training, inference, and HPC simulations.
Broader FP8 (data processing method) support — enhancing AI inference capabilities with ROCm 6.2
The extensive support for FP8 (data processing method) in ROCm can significantly improve the process of running AI models, particularly in inference. It helps address key issues such as memory bottlenecks and high latencies associated with higher precision formats, enabling the processing of larger models or batches within the same hardware constraints, thus achieving more efficient training and inference processes. Additionally, the reduced precision computation of FP8 (data processing method) can reduce latency in data transfer and computation.
ROCm 6.2 expands support for FP8 (data processing method) across its ecosystem, achieving performance and efficiency enhancements in various aspects from frameworks to libraries.Transformer Engine: Enhanced FP8 GEMM support in PyTorch and JAX through HipBLASLt, maximizing throughput and reducing latency compared to FP16/BF16.
XLA FP8: JAX and Flax now support FP8 GEMM via XLA to boost performance.
vLLM Integration: Further optimization for vLLM capabilities with FP8.
FP8 RCCL: RCCL now handles FP8-specific collective operations, expanding its versatility.
MIOPEN: Supports FP8-based Fused Flash attention mechanisms for increased efficiency.
Unified FP8 Header Files: Standardizing FP8 header files across libraries to simplify development and integration processes.
With ROCm 6.2, AMD once again demonstrates its commitment to providing powerful, competitive, and innovative solutions for the AI (Artificial Intelligence) and HPC (High-Performance Computing) domains. The release of this version signifies that developers have the tools and support needed to push boundaries, further strengthening ROCm's confidence as the preferred open platform for next-generation computing tasks. Join us in embracing these advancements and elevate your projects to unprecedented levels of performance and efficiency.